基于Hadoop的食品安全预警系统架构
摘 要:针对海量的食品安全数据,传统食品安全预警系统架构往往存在运算速度慢、处理效率低等缺点,本文提出了一种基于Hadoop的食品安全预警系统架构,该架构以Hadoop框架为基础,分别设定了基于分布式爬虫的数据获取模块、基于数理统计和数据挖掘的数据分析、存储模块和预警模块。该架构具有层次清晰、扩展性高等特点,适合运用和推广。
关键词:Hadoop 食品安全 系统
食品安全指的是食品应当符合无毒害、对人体健康不造成任何急慢性危害,并且包含一定营养物质的特点。为了维护人民群众在食品安全与保障方面的相关权益,国内外建立了相应的食品安全预警和快速反应系统,来预防食品突发性、群发性事件。
目前较大的食品安全预警系统有:世界卫生组织(WHO)的国际食品安全网络(INFOSAN)、欧盟食品和饲料快速预警系统(RASFF)、美国疾病和预防中心(CDC)的FoodNet系统等[1]。我国国家质检总局建立了食品安全风险快速预警与快速反应系统,来快速报告和处理食品突发事件[2];香港行政区在2007年启动了食品安全快速预警系统(RAS);北京市在2012年启用了食品安全短信预警平台,来防治食品安全突发事件。
国内外通用的系统大多采用检验检疫产生的数据来对食品安全进行预警,这些数据的特点是,准确、可靠且容易被处理。然而,食品安全数据不仅限于此来源,在互联网络中具有海量的食品安全相关信息。这些信息大多与媒体报导、网友发帖、政府发布为主要来源,具有多种来源渠道和广泛的受众[3]。因而,有效地利用网络中海量的食品安全数据来搭建食品安全预警系统具有广阔的前景。
Hadoop是一个使用Java编写的开源分布式框架,它在存储和计算方面(分别由Hadoop分布式文件系统HDFS和Map/Reduce编程模型实现)与普通的现有的单节点计算相比具有显著优势[4]。使用Hadoop平台来获取和处理网络信息、搭建食品安全预警系统,具有处理速度快、并行化程度高、预警及时的特点。
1 Hadoop开发环境搭建
本文使用的Hadoop版本是其在Linux平台上的一个Java开源版本。在开源操作系统Linux环境中进行Hadoop开源平台的搭建,首先需要安装Java软件开发工具包(Java SE Development Kit,JDK)并配置环境变量,使得基于Java语言的Hadoop代码能够顺利运行;然后进行网络桥接和配置,将各物理机和虚拟机的IP地址设置在同一个网段,且固定IP;最后进行Hadoop平台的安装及配置,并监控各个节点的运行状况。以下我们将详细阐述各个阶段的配置过程。
1.1 网络桥接和配置
为使分布式平台的各主机节点能被其他节点通过网络地址访问到,将网络地址改写为同局域网内的固定IP,因为本文中使用了KVM虚拟机技术配置网络,因而需要对虚拟机进行网络桥接,使主机和节点在同一个网段上。本文使用的是bridge的网络连接方式,将宿主机和客户机设定在同一个局域网中,有利于相互访问。
另外,为了使得各个虚拟机之间能够顺畅访问,我们关闭了Linux系统中自带的防火墙功能。为了保障Hadoop系统间的信息安全,我们使用SSH协议来为远程登录会话提供安全性。在创建一对密钥后,将公用密钥寄放在NameNode宿主机中,实现NameNode和DataNode之间的连通(DataNode之间并无网络相连)。在通信过程中,我们使用RSA加密算法加密。网络桥接和配置完成后,形成了倒树状的逻辑结构。
1.2 Hadoop平台的安装及配置
本文使用两台服务器,分别部署2个和3个虚拟机来假设Hadoop平台,共计为7个节点。这些节点均为CentOS系统,并统一安装了JDK1.7.0_25。本系统使用Apache基金会发布的Hadoop2.2.0版本,该版本的特点为运行较为稳定,且与JDK1.7.0_25互相兼容。在配置Hadoop的过程中,需要在hadoop/slaves文件中加入DataNode的IP地址,使得Hadoop在项目运行过程中可通过该IP访问DataNode。我们将服务器的/etc/hosts文件中设置为对应的主机名和固定IP地址,来方便SSH的访问。
然后配置SSH的RSA加密访问,首先使用ssh-keygen生成一对密钥,接着将公钥/root/.ssh/id_rsa.pub拷贝到DataNode服务器中,使得DataNode可与NameNode进行安全的数据交流。接下来我们启动hadoop并进行测试,首先启动NameNode,接着分别启动DataNode,并设置好日志存储位置,以便对任务运行状况进行监视。
1.3 在Hadoop平台上进行任务部署
本系统通过网页http协议访问相关端口(定为localhost:50030端口和localhost:50070端口)前者监控MapReduce任务的运行情况,资源占用等,后者为监控各个DataNode子节点的运行状况。如图1所示。
同时,可通过控制台的hadoop命令来运行所编写的Java程序,首先需要将编写的Java程序导入到HDFS分布式文件系统中,然后运行hadoop命令对程序进行执行。在程序执行的过程中,同样可使用网页端口来监视各节点资源分配情况,任务处理状况和查看运行日志。
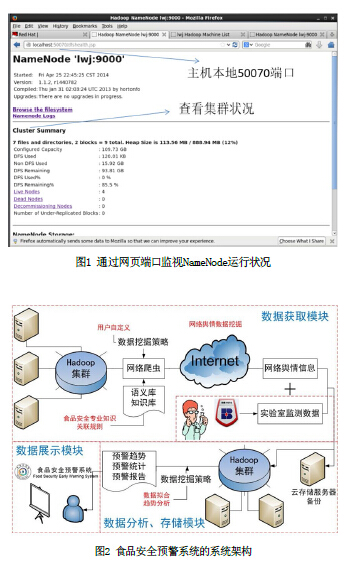
2 食品安全预警系统架构
本系统的系统架构如图2所示。主要分为数据获取模块、数据分析存储模块和数据展示模块。其中,数据获取模块首先分析用户自定义的数据挖掘策略,然后通过网络爬虫结合食品安全数据库来对网络中的食品安全数据进行爬取。所获取到的网络舆情信息结合实验室监测数据,共同存储在云存储服务器中,进行数据备份。
在数据分析模块,我们使用了统计学和数据挖掘的分析方法,来对数据获取模块得到的食品安全信息进行处理,从而得到食品安全预警信息。我们从食品安全数据的时间分布、空间分布以及违禁项分布3个方面来分析所获取的数据。最后将所得到的预警信息生成食品安全预警报告,并将此报告通过数据展示模块汇报给用户。
我们搭建的Hadoop集群在该食品安全预警系统中有两处应用。首先在使用爬虫进行数据获取的时候,爬虫程序架设在Hadoop集群之上,充分利用集群的运算和处理性能,来使用爬虫进行并行化爬取食品安全数据;其次,在进行数据挖掘和分析的过程中,Hadoop集群被用于处理和分析网络中获取的食品安全数据,最终得出食品安全预警信息,输出到数据展示的用户端。
3 数据获取模块
数据获取模块以爬虫技术的应用为核心,主要分为Frontier模块、ToeThread模块和Processor模块,这3个模块的作用分别为:爬取网页中的URI,向线程提供链接;实现多线程运行;实现爬虫处理信息的逻辑结构等。见图3。
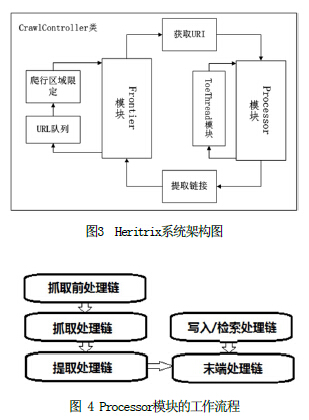
Frontier模块用于向线程提供链接,它的作用主要是:保存等待处理的链接、记录那些已经被处理过的链接。在Frontier实现的过程中,为了解决大数据量,多并发存在的问题,因而实现了Berkeley Database嵌入式数据库,它能够按“key/value”方式来保存数据。
在ToeThread模块中,提供了一个标准的线程池ToePool,用于管理所有的抓取线程,从而更有效更快速的抓取网页内容。在Processor模块中,首先进行预抓取,接着进行网页抓取活动,然后进行网页内容的提取,并进行写入,最后完成抓取活动的收尾工作。如图4所示。
4 食品安全预警系统
功能设计
为了从数据获取模块获得的数据中提取预警信息,本系统设计了预警数据分析与挖掘模块。通过对网络食品安全信息进行数据分析和挖掘后,当发现预警因子的数据值超过预警设定值时,预警系统发出预警信息,并呈递给用户处理。以下小节将详细叙述该预警过程:
4.1 预警因子的确定
参考国家对食品安全的检测标准,我们将预警因子设定为以下几个分类:添加剂、重金属超标、兽药残留、微生物超标、违禁物添加。并对这几类因子设定了不同的预警阈值。比如,在国家标准中,添加剂、重金属、兽药残留和微生物这4个指标允许有一定量的检出,但不允许超过国家限定的含量。因而,当这几类预警因子达到一定标准的时候,预警提示才会发布;而作为违禁物添加的项目,国家规定不得检出,这类物质一旦出现,无论含量是否较大都将发布预警提示。
4.2 预警信息的获取
本系统通过两类方法来获取食品安全预警信息。
数据分析的方法,主要是统计学分析和数据拟合。我们将各项食品的预警因子在时间上进行趋势拟合,如近期拟合曲线明显呈上升趋势(如曲线斜率超过限定值),则认为该食品的此项预警因子的检出呈明显上升趋势,此时即发布预警信息;否则则认为近期该项目处于安全状况,不发布预警信息。
数据挖掘方法,本项目使用关联规则挖掘方法,来对各项因子之间的潜在规则进行探寻。例如,通过历年数据关联规则挖掘,发现当预警因子A明显升高时,预警因子B也随之升高,且A和B出现的相关性R2大于0.8,则认为预警因子A和B呈强相关性。依照此规律,当预警因子A的检测超过阈值时,应当考虑同时发布预警因子B的预警信息。
5 总结和展望
本文通过对Hadoop平台和爬虫技术的研究,提出了一种基于Hadoop的食品安全预警系统架构。该架构以Hadoop分布式系统为底层框架,结合使用爬虫技术来获取食品安全数据。该架构适合应用于对海量网络食品安全数据进行处理和预警。后续工作可集中在爬虫策略的改进上,使其爬取过程更适合食品安全网站的信息发布特点;也可进一步研究Hadoop平台上的任务调度和优化问题,进行任务调度、优化及负载的实验,使该系统达到最合理的任务分配方式。
参考文献
[1] Marvin H J P, Kleter G A, Prandini A, et al. Early identification systems for emerging foodborne hazards [J]. Food and Chemical Toxicology, 2009, 47(5):915-926.
[2] Law W T Y, Chiu D K W, Hu H, et al. An advanced rapid alert system for food safety[C]//e-Business Engineering (ICEBE),2012 IEEE Ninth International Conference on. IEEE, 2012:361-366.
[3] 刘文,李强.食品安全网络舆情监测与干预研究初探[J].中国科技论坛, 2012(7):44-49.
[4] 王彦明.近年来Hadoop国内研究进展[J].现代情报,2014,34(8):4-19.

[责任编辑:]

相关阅读
- (2014-06-16)家乐福与您一起努力建设食品安全诚信
- (2014-06-16)以诚信保障安全 中国食品安全诚信宣言大会在京召开
- (2014-06-16)张志刚:提高诚信自律,共为食品安全献计献策
- (2014-06-17)食品安全治理:挖根去皮方得实质效果
- (2014-06-17)搞好食品安全农产品生产是关键
 Mettler-Toledo 在中国国际渔业博览会上展示创新的产品
Mettler-Toledo 在中国国际渔业博览会上展示创新的产品
 食品异物问题频发?是时候了解X射线检测了
食品异物问题频发?是时候了解X射线检测了
 开拓科技创新,撬动橡塑业高质量发展
开拓科技创新,撬动橡塑业高质量发展
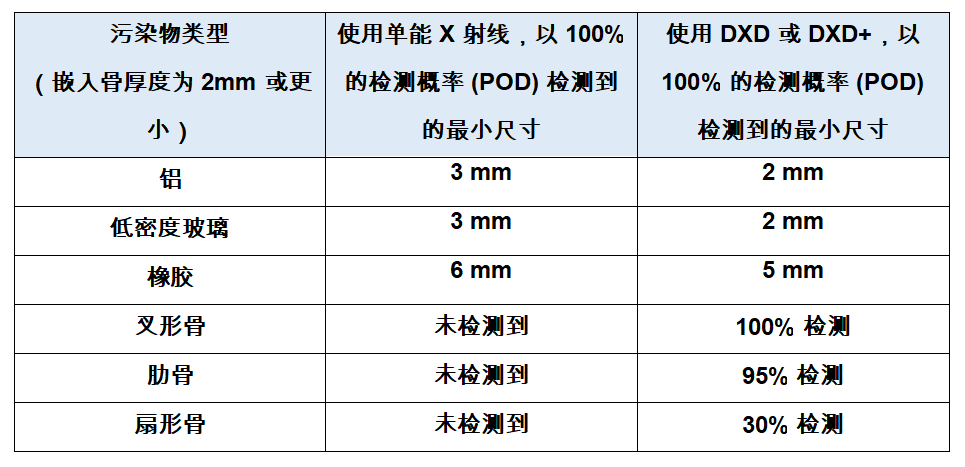 梅特勒托利多针对“难以发现”的污染物推出高品质X射线检
梅特勒托利多针对“难以发现”的污染物推出高品质X射线检
 探索婴幼儿辅食市场高质量发展之路,为宝宝成长保驾护航
探索婴幼儿辅食市场高质量发展之路,为宝宝成长保驾护航
 《食品安全最佳实践白皮书(2021-2022年)》四大主题发布
《食品安全最佳实践白皮书(2021-2022年)》四大主题发布
 《保健食品真实世界研究通则》团标技术审查与特食跨
《保健食品真实世界研究通则》团标技术审查与特食跨
 凝聚全球食饮智慧 SIAL西雅展国际化水平再创新高
凝聚全球食饮智慧 SIAL西雅展国际化水平再创新高
 精准把控 高质发展,第三届微生物安全与应用会议在
精准把控 高质发展,第三届微生物安全与应用会议在
 《食品行业科技创新白皮书》重磅发布!
《食品行业科技创新白皮书》重磅发布!






参与评论